32 WorldCereal - A Global Effort for Crop Mapping
32.1 Introduction
Reliable, timely information on what crops are grown where and when, is vital for national and global food security [1]. For national statistical offices (NSOs), such data underpin production estimates, food balance sheets, and policy decisions. Yet, accurate crop statistics remain difficult to obtain. Field surveys and administrative reports are costly, slow, and often incomplete. In many countries, especially where smallholder farming dominates, data collection is further constrained by fragmented landscapes and limited budgets.
Earth observation (EO) has become an important complement to traditional data sources, particularly since the advent of free and open high resolution (10 m) radar and optical data from the Copernicus Sentinel-1 and -2 missions in 2017. [2] provide an exhaustive overview of recent EO-based crop mapping initiatives, both at global and regional scale. Most crop mapping applications to date have been case-specific: models are typically developed for the most dominant crops in a single country, trained on a single year using local ground truth data, tuned to local conditions, and are rarely transferable. Several global maps for individual crops have been released, but because training data and models are not disclosed, these efforts cannot easily be reproduced or extended.
Two obstacles have limited broader uptake. First, reference data – the ground truth needed to train and validate models – are scarce, heterogeneous and often closed-source. Second, models are difficult to transfer in space and time: a classifier trained on maize in Argentina may perform poorly in Ethiopia, or even in Argentina in a different year. For NSOs, this means EO-based crop mapping approaches and derived maps often lack the consistency and reliability needed for official statistics.
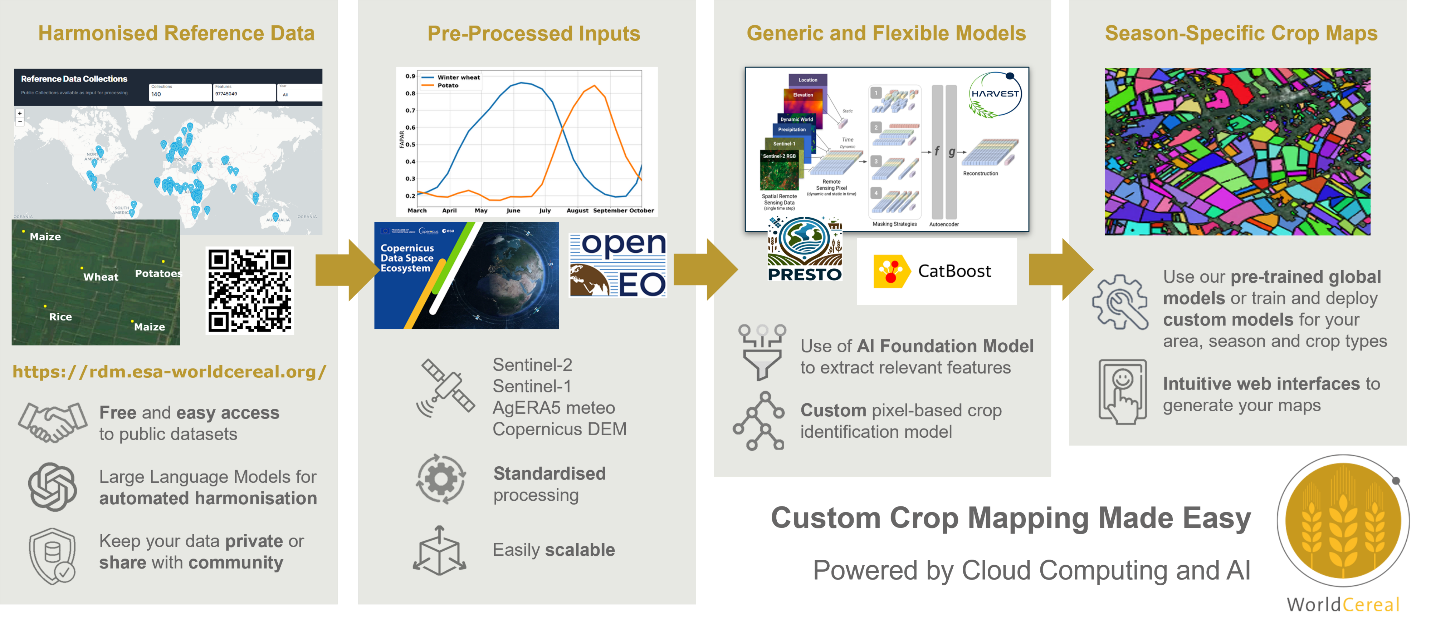
The WorldCereal project, funded by the European Space Agency, was launched in 2020 to overcome these barriers. Its ambition is to create an open, scalable, and reproducible local-to-global crop mapping system (Figure 32.1). It rests on two pillars. The first is harmonised reference data, managed through the WorldCereal Reference Data Module (RDM). The second is a transferable classification system that converts satellite time series into crop maps. The first version (v1, 2023) used expert-defined features and machine learning to produce the world’s first global seasonal crop maps at 10 m resolution for 2021 [3]. The second version (v2) replaces expert features with machine-learned features, so-called embeddings, using a geospatial foundation model, improving transferability across regions and seasons [4]. In addition, WorldCereal is designed with usability in mind. A web-based Processing Hub lets users generate their own maps by selecting a region and season of interest, without coding. Users can also add their own - private - reference data to further tailor outputs to their specific needs. By doing so, users can benefit from globally learned crop-specific representations of satellite data and finetune it to their local needs with their own data.
For NSOs, WorldCereal offers a way to complement and strengthen agricultural statistics. By providing consistent, timely, and spatially detailed crop maps, it enables more accurate production estimates and supports early warning of food shortages. Importantly, all data, models, and workflows are transparent and reproducible. In the following sections, we describe the two pillars of the system and illustrate, through two experiments, temporal robustness and spatial transferability, key challenges for official statistics.
32.2 Reference Data: The WorldCereal RDM
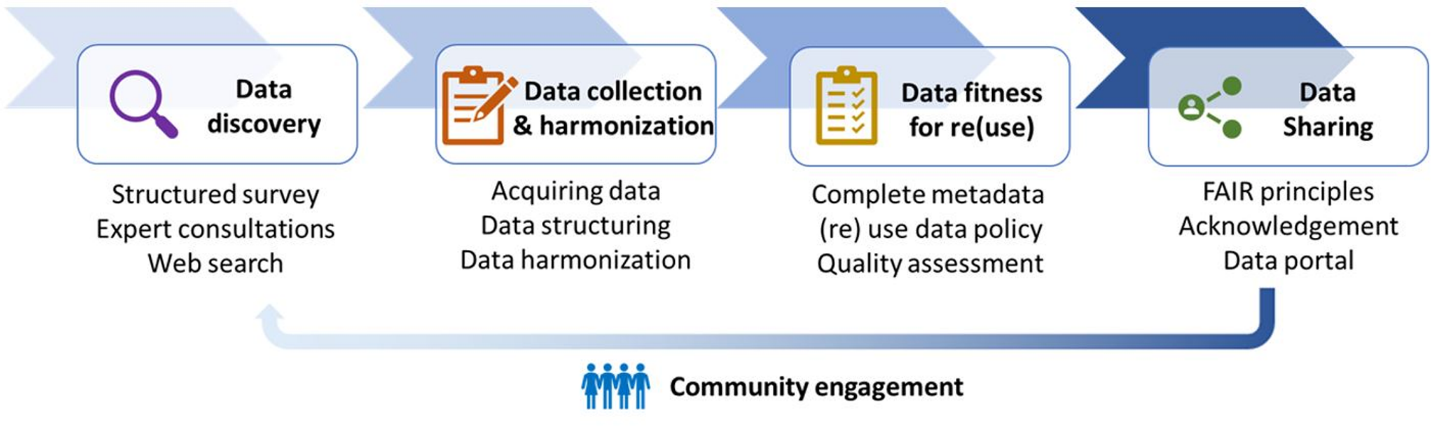
The WorldCereal Reference Data Module (RDM; [5]) addresses one of the biggest bottlenecks in crop mapping: the lack of accessible, harmonised reference data. Many crop type data collection campaigns have been initiated in the past, but typically remain disconnected, each characterized by its own data formats, nomenclature, license and access point. WorldCereal has set up a community driven framework for reference data collection and re-use, covering data discovery, collection, harmonization, documentation, quality assessment and publication (Figure 32.2, [6]).
The RDM integrates data from diverse sources including field surveys, parcel registration systems, citizen science platforms like LACO-Wiki and Geo-Wiki, and institutional contributions from GEOGLAM JECAM sites, CGIAR centers, and NASA Harvest. All records are harmonised to a common crop and land cover legend, enriched with metadata, and assigned a confidence score reflecting spatial, temporal, and thematic quality. High-quality data, such as farmer declarations, receive the strongest scores, while crowd-sourced observations are more variable. These scores can be used to weight samples during model training.
New data can be added through an intuitive web interface, where organisations and individuals upload datasets that are automatically harmonised. Contributors decide whether their data remain private, can be used for training the official WorldCereal algorithms, or are published openly. This flexibility encourages sharing while respecting ownership.
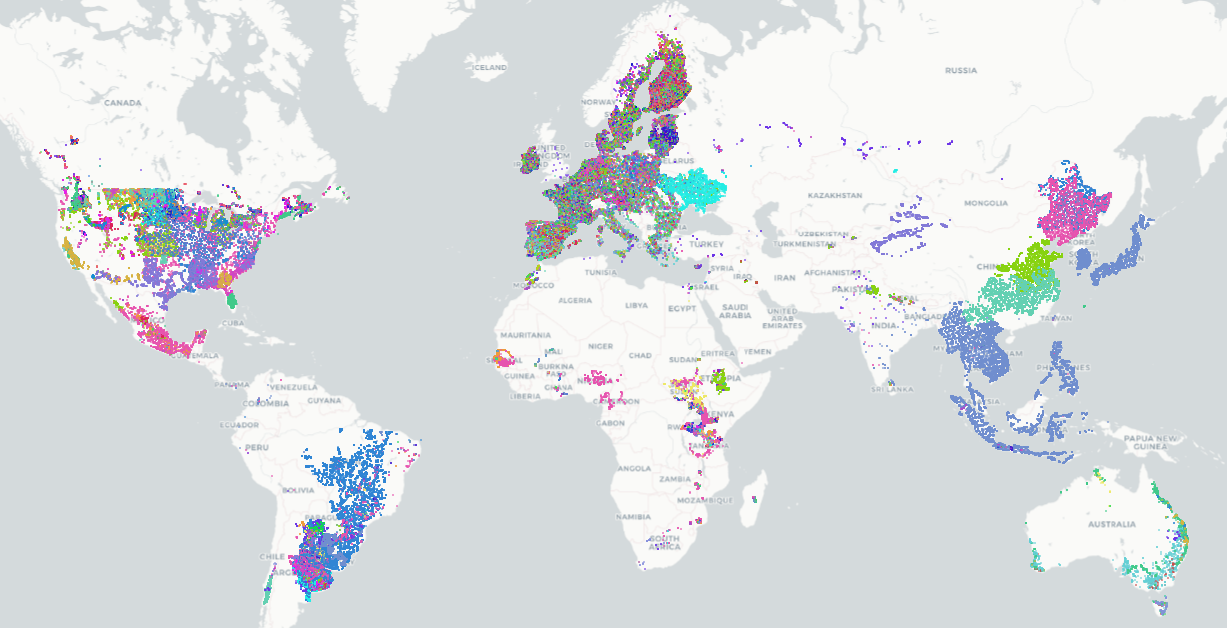
The RDM can be accessed via a web portal or an API for integration into processing workflows. Furthermore, a dedicated Jupyter Notebook allows anyone to interactively explore, access, filter and download the publicly available data. Finally, individual datasets are also published on Zenodo to ensure long-term availability [7]. By end of 2025, the RDM contained close to 111 million harmonised observations on land cover and crop type, spread across 159 datasets (Figure 32.3). For NSOs, the RDM reduces the cost of collecting training data, allows them to contribute national datasets while retaining control, and enhances comparability of crop statistics across countries. In short, it is the backbone of WorldCereal: a trusted, continuously growing library of reference data ensuring both global scalability and local customizability.
32.3 Classification System: From Expert Features to Foundation Models
The second pillar of WorldCereal is its classification system – the algorithms that transform satellite time series into crop maps. The first version, developed in 2021, relied on expert-defined temporal and spectral features from Sentinel-1 and Sentinel-2 imagery, combined with auxiliary data such as elevation and meteorological variables [8]. These features were used to train a CatBoost classification model, a gradient-boosted decision tree algorithm. The system successfully produced the first global seasonal crop maps at 10 m resolution [3], demonstrating the feasibility of large-scale crop mapping. However, while accurate in regions with ample training data, its transferability to data-scarce regions was limited [9].
32.3.1 The promise of geospatial foundation models
The evolution of WorldCereal into its second phase coincided with a turning point in Earth Observation: the emergence of geospatial foundation models ([10]; [11]). As discussed in Section 32.2, the limited availability and restricted sharing of labelled reference data remain key bottlenecks for large-scale agricultural mapping. In contrast, petabytes of multi-sensor satellite imagery are freely accessible yet largely unlabelled. Foundation models bridge this gap by learning generic representations from unlabelled data and transferring them to specific mapping tasks with only limited labelled samples. Their purpose is to reduce the dependency of operational mapping systems on extensive, curated reference datasets, and to overcome the supervised-learning dependency on large, localised training samples.
For a global, operational-scale system such as WorldCereal, this potential is highly attractive, but it also raises strict requirements which is why to date, geospatial foundation models have rarely been deployed operationally and with success. According to our deployment protocol, requirement-setting is Step 1 in operationalising a foundation model (adapted from [4]). The key requirements defined for the WorldCereal crop mapping application include:
Computationally friendly: The system must run within constrained compute budgets, memory footprints and latency bounds typical of production workflows, rather than purely research-scale setups. It must also support seasonal re-runs and global coverage without prohibitive costs. Lightweight finetuning or downstream application by users is key to successfully bring the power of these models to individual users.
Operationally deployable: The model must be robust, maintainable and suitable for an operational environment (not just a research prototype). This means predictable performance across regions and seasons, minimal manual tuning, reproducibility, monitoring and support for production-grade workflows.
Easy ingestion into an existing mature framework: WorldCereal already builds on a mature processing architecture, workflows and modules. Any new foundation model must integrate smoothly into such a workflow, enabling reuse of existing preprocessing, classification downstream layers, cloud infrastructure and user-interfaces, with minimal re-engineering.
Spatial and temporal generalisation: Since the system must map globally and seasonally, the chosen model must generalise across geography (diverse agro-ecological zones) and time (across years, changing climate conditions, changes in satellite data availability).
Data efficiency and adaptability: Because labelled training data remain limited in many regions, the model must be able to fine-tune or adapt with only a small number of local samples, and still deliver acceptable accuracy.
Rather than adopting a foundation model purely on promise, WorldCereal Phase II therefore undertook a rigorous benchmarking campaign to assess whether existing geospatial foundation models could satisfy all of these requirements. This campaign involved integrating such model into the classification pipeline, fine-tuning it with available reference data, and evaluating its performance across diverse agro-ecological zones, with particular attention to compute cost, runtime behaviour, robustness of transfer (across space and time), and integration into the existing system.
32.3.2 Integrating Presto in WorldCereal
During development, several foundation models were evaluated that had been released at that time (e.g. SatMAE, CROMA, ScaleMAE, Presto), and Presto was selected for its efficiency, open-source availability, and compatibility with the WorldCereal processing architecture, aligning well with our requirements listed in Section Section 32.3.1. Presto, developed by NASA Harvest, is a lightweight transformer-based feature extractor pre-trained on global Sentinel-1/2 time series enriched with topography and meteorology (Figure 32.4). It learns generalizable patterns without requiring labels, and its embeddings can be fine-tuned with relatively few reference samples, significantly improving robustness where data are scarce.
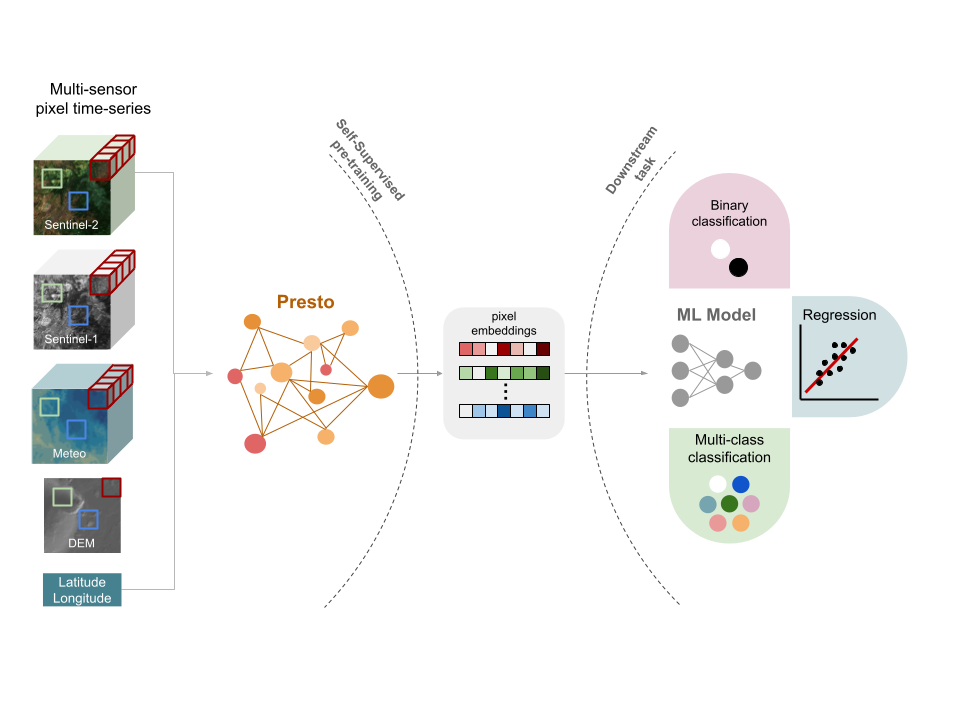
Importantly, the WorldCereal system has been designed modularly, allowing future integration of alternative foundation models that produce similar spatio-temporal embeddings with minimal adaptation effort.
The embeddings generated by such models capture recurring spectral–temporal patterns of vegetation dynamics and can be used in complementary ways:
as frozen feature vectors driving a lightweight downstream classifier,
after an additional self-supervised alignment step to adapt to regional data distributions, or
through end-to-end fine-tuning when computational resources and labels are available.
This flexibility enables the same pretrained backbone to support both global production models and national implementations enhanced with local reference data. NSOs and other users can thus retrain lightweight classifiers for their own regions, combining the robustness of a global pretraining with the adaptability needed for national statistical applications.
Extensive experiments on cropland and crop type mapping in [4] confirm the strong spatial and temporal generalization achieved through such pretraining. Compared to both the Phase I feature-engineered baseline and CatBoost classifiers trained directly on raw satellite time-series, foundation-model variants consistently deliver higher accuracy and more stable performance when transferred across regions and years (Table 32.1). An additional self-supervised learning (SSL) step prior to model finetuning to make the model accustomed to specific pre-processing routines did not yield an increase in performance. Even when only a small portion of local data is available for fine-tuning, the pretrained representations preserve most of their predictive power, demonstrating the value of general knowledge distilled from global unlabelled imagery.
| Method/Model | Random | Geographic | Temporal |
|---|---|---|---|
| Baseline (feature engineering) | 0.856 | 0.81 | 0.83 |
| Unprocessed CatBoost | 0.828 | 0.777 | 0.874 |
| Finetuned Presto-Rnd | 0.81 | 0.705 | 0.806 |
| Finetuned Presto | 0.861 | 0.829 | 0.886 |
| SSL + Finetuned Presto | 0.861 | 0.826 | 0.884 |
Together, these advances make the WorldCereal v2 classification system more scalable, transferable, and user-friendly, while remaining computationally efficient and deployable on standard cloud infrastructure. The next section illustrates how these principles materialize in practice through two use cases focused on temporal robustness and spatial transferability, showing how a foundation-model backbone underpins reliable crop-mapping results.
32.4 Real world demonstration
Two experiments illustrate the robustness and transferability of the new WorldCereal classification system. They focus on temporal and spatial challenges, with technical details available in the accompanying notebook. All experiments have been conducted in Europe, covering the following crop types: maize, rapeseed, sunflower, vegetables & tubers (combination of vegetables, potatoes and sugar beet), spring cereals, winter cereals and other crops. The latter is comprised of fibre crops such as cotton, leguminous crops (peas, beans, alfalfa, clover) and temporary grasslands. Cereals are defined here as a combination of wheat, barley and rye.
The first experiment covers temporal robustness. A model trained on reference data from France covering multiple years (2018, 2019, 2020 and 2022) was applied to an unseen year (2021). Results are provided in Table 32.2 and illustrate that Presto enables decent transfer across years, even to years not represented in the training data (compare columns 1 and 2). This illustrates the key benefit of having multi-year representation in the training data.
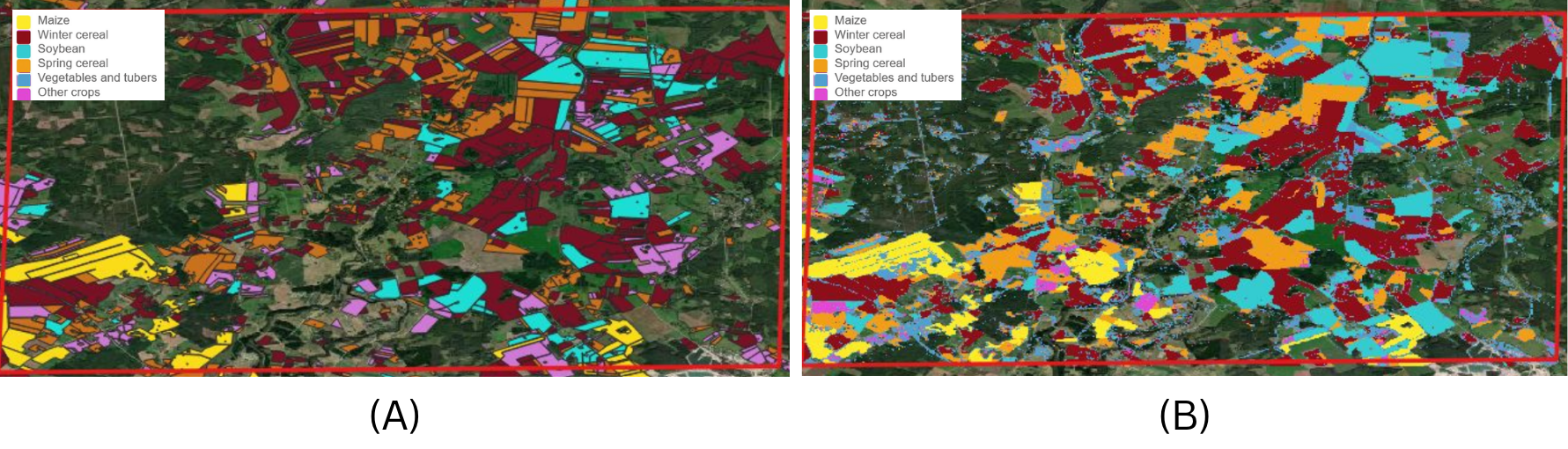
The second experiment examines spatial transferability. The same model trained on multi-year data from France is applied to Latvia, more than 2,500 km to the north east of France. As expected, performance drops when moving to an area with different climatological and agricultural characteristics (Table 32.2, column 3). Yet, by gradually adding even small amounts of local reference data, accuracy improves significantly. The initial overall F1 score of 0.65 improved to 0.73 upon adding just 500 Latvian samples, to 0.75 when adding 1000 samples and reached 0.79 upon adding 3000 samples. Improvements were observed across all crop types (Table 32.2, column 4). Despite having F1 scores below 0.80, Figure 32.5 shows a good match between the generated crop type map and validation data for a small area located near the town of Vilani in the Latgale region, Latvia. This demonstrates the value of combining global knowledge embedded in foundation models with targeted national inputs. For NSOs, the implication is clear: even modest investments in local reference data can greatly enhance national crop maps.
| Evaluation dataset | France multi-year | France 2021 | Latvia 2021 | Latvia 2021 |
|---|---|---|---|---|
| Maize | 0.87 | 0.84 | 0.77 | 0.85 |
| Rapeseed | 0.93 | 0.89 | 0.81 | 0.86 |
| Spring cereals | 0.76 | 0.77 | 0.65 | 0.71 |
| Sunflower | 0.84 | 0.82 | / | / |
| Vegetables and tubers | 0.84 | 0.83 | 0.58 | 0.65 |
| Winter cereals | 0.84 | 0.85 | 0.78 | 0.85 |
| Other crops | 0.77 | 0.76 | 0.29 | 0.59 |
| Overall | 0.83 | 0.82 | 0.65 | 0.75 |
Together, these cases show that foundation models enable classification systems that are broadly transferable yet adaptable to local needs. Rather than replacing national data collection, WorldCereal complements it by providing a scalable backbone strengthened by local inputs.
32.5 Discussion
The experiments from previous section highlight key lessons. Temporal robustness is critical for producing consistent time series of crop statistics and can be achieved using a multi-year training approach. Spatial transferability shows the potential of global systems in regions with limited data infrastructures. While performance declines when applying models far from their training domain, foundation models maintain usable accuracy and can be rapidly improved with small local datasets. The specific examples presented in the notebooks showcase how our advanced cloud computing capabilities through innovations like the OpenEO processing framework have significantly lowered the technical barrier for any organization to adopt often complex data processing pipelines based on satellite EO data. For NSOs, global systems like WorldCereal provide an immediate and easy-to-use baseline, while national contributions enhance quality and relevance.
Moving forward, openness and collaboration are central. The RDM demonstrates that pooling datasets from diverse sources and harmonising them to a common standard creates a collective resource that benefits all. The classification system shows how advanced artificial intelligence and machine learning can be operationalised in ways accessible to non-specialists. Together, these embody open science that is both technically innovative and institutionally relevant.
It is important to underscore remaining limitations of this system. Global models will rarely match the accuracy of bespoke local systems, especially for specific crops of national importance. Reference data gaps persist in Africa, Asia, and Latin America and will constrain performance until addressed. Further advances will depend on both expanding open reference data and improving transferable foundation models, complemented by innovative data-collection approaches - such as semi-automated classification of street-view imagery or smart sampling from existing crop type maps - and sustained investment in data sharing, harmonization, and capacity building.
Finally, it is important to stress that crop type maps as such should not be directly used to infer national statistics through pixel counting, but rather should be accompanied by statistically sound surveys to correct for any bias present in the maps. Regardless, accurate crop type maps generated through WorldCereal can be used for stratification purposes during the design phase of such statistical surveys and additionally provide valuable insights into temporal evolutions in crop type distributions and cropping practices within a country.
32.6 Conclusion
WorldCereal represents a new paradigm for global crop mapping. By combining harmonised reference data with transferable classification systems, it demonstrates how EO can provide consistent, timely, and scalable information to support agricultural monitoring worldwide. The first version proved feasibility; the second advances the field with foundation models that improve robustness across years and regions.
For NSOs, WorldCereal offers both a baseline and a partnership. It provides globally consistent products that fill immediate data gaps, while also enabling integration of national datasets to customise outputs. This dual role – global baseline and national adaptation platform – makes it especially relevant for official statistics.
Looking ahead, continued growth of the RDM, refinement and diversification of foundation models, and stronger user engagement will be key. By embracing openness, collaboration, and innovation, WorldCereal is helping to build a future in which reliable crop statistics are available to all countries, supporting better decisions for food security and sustainable agriculture.
Data and code availability
The code and data for reproducing the example from the demonstration Section are available on GitHub.
[1]
I. Becker-Reshef et al., “Crop type maps for operational global agricultural monitoring,” Scientific Data, vol. 10, no. 1, Mar. 2023, doi: 10.1038/s41597-023-02047-9.
[2]
C. Zhang et al., “Remote sensing for crop mapping: A perspective on current and future crop-specific land cover data products,” Remote Sensing of Environment, vol. 330, p. 114995, Dec. 2025, doi: 10.1016/j.rse.2025.114995.
[3]
K. Van Tricht et al., “ESA WorldCereal 10 m 2021 v100.” Zenodo, 2023, doi: 10.5281/ZENODO.7875104.
[4]
C. Butsko et al., “Deploying geospatial foundation models in the real world: Lessons from WorldCereal.” arXiv, 2025, doi: 10.48550/ARXIV.2508.00858.
[5]
S. Karanam et al., “WorldCereal reference data module (RDM).” International Institute for Applied Systems Analysis (IIASA), 2024, doi: 10.60566/80P50-6Z433.
[6]
H. Boogaard et al., “Building a community-based open harmonised reference data repository for global crop mapping,” PLOS ONE, vol. 18, no. 7, p. e0287731, Jul. 2023, doi: 10.1371/journal.pone.0287731.
[7]
H. Boogaard et al., “WorldCereal harmonized reference datasets - extended and updated.” Zenodo, 2025, doi: 10.5281/ZENODO.17288872.
[8]
K. Van Tricht et al., “WorldCereal: A dynamic open-source system for global-scale, seasonal, and reproducible crop and irrigation mapping,” Earth System Science Data, vol. 15, no. 12, pp. 5491–5515, Dec. 2023, doi: 10.5194/essd-15-5491-2023.
[9]
M. Lesiv, “WorldCereal phase 1: Validation report,” 2024, doi: 10.5281/ZENODO.13908673.
[10]
G. Tseng, R. Cartuyvels, I. Zvonkov, M. Purohit, D. Rolnick, and H. Kerner, “Lightweight, pre-trained transformers for remote sensing timeseries.” arXiv, 2023, doi: 10.48550/ARXIV.2304.14065.
[11]
K. Klemmer, E. Rolf, C. Robinson, L. Mackey, and M. Rußwurm, “SatCLIP: Global, general-purpose location embeddings with satellite imagery.” arXiv, 2023, doi: 10.48550/ARXIV.2311.17179.